In questo blog post risponderò al quesito posto da Giuliano su messenger 💭:

In pratica, Giuliano mi sta chiedendo come fare JOIN tabellari tra 70 vettori e non le classiche due tabelle.
Il quesito risulta apparentemente complesso, visto che normalmente una join tabellare si esegue tra due tabelle, quindi la prima cosa che viene in mente è quella di iterare il processo di join, ma in realtà la soluzione è molto più semplice; sotto descriverò diverse approcci per risolvere il quesito.
INTRO: Come fare una JOIN tabellare

A partire da due tabelle (shp001, shp002), ognuna con un campo correlato (che ha gli stessi valori in entrambe le tabelle, per esempio id), per effettuare una JOIN tabellare usando ogr2ogr e la riga di comando, lanciare questo script:
ogr2ogr -sql \
"SELECT t1.id AS id, t1.nome AS nome, t1.value AS val_shp001, t2.value AS val_shp002 \
FROM shp001 t1 JOIN './shp002.shp'.shp002 t2 \
ON t1.id=t2.id" \
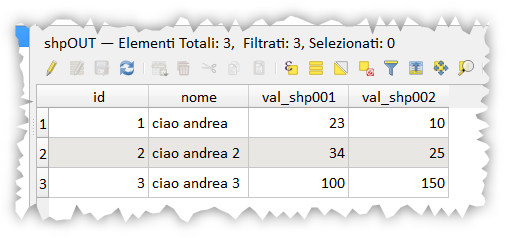
./shpOUT.shp ./shp001.shp
risultato:
OSSERVAZIONI
Realizzare una JOIN tabellare è cosa semplice e veloce, ma realizzare molte JOIN consecutive non è altrettanto semplice soprattutto se volessimo iterare lo script ogr2ogr sopra descritto, quindi, occorre cambiare processo: “un probabile approccio risolutivo potrebbe essere quello di convertire i vettori (dal shp002 al shp070) in semplici tabelle CSV e fare un merge orizzontale tra tutti i file, infine, fare una sola JOIN tabellare tra il primo vettore shp001 (che conserverebbe la geometria) e il tabellone risultante dal merge precedente”. [idea di Andrea Borruso]
La conversione di formato, da vettore a tabella CSV, facilità l’unione dei file; sotto alcuni esempi su come fare la conversione e la multi-join orizzontale:
RIGA DI COMANDO
Prima soluzione ambiente bash (linux)
#!/bin/bash
#### RIFERIMENTI #####
# ogr2ogr : https://gdal.org/programs/ogr2ogr.html
# miller : https://github.com/johnkerl/miller
####################
set -x
set -e
set -u
set -o pipefail
# crea i CSV e ordina i CSV per ID
for i in *.shp; do
name=$(basename "$i" .shp)
ogr2ogr -f CSV -sql 'select id,value from '"$name"'' "$name".csv "$name".shp
mlr -I --csv sort -n id then cut -f value then rename value,value_"$name" "$name".csv
done
# unisci i CSV in un unico CSV
paste -d "," shp*.csv > all.csv
# estrai il primo shp e convertilo in CSV
primoShape=$(find ./ -iname "*.shp" -type f | head -n 1)
tmp=$(basename "$primoShape" .shp)
ogr2ogr -f CSV tmp.csv "$tmp".shp
# estrai da questo ultimo soltanto la colonna id
mlr -I --csv cut -f id then sort -n id tmp.csv
# crea il file finale
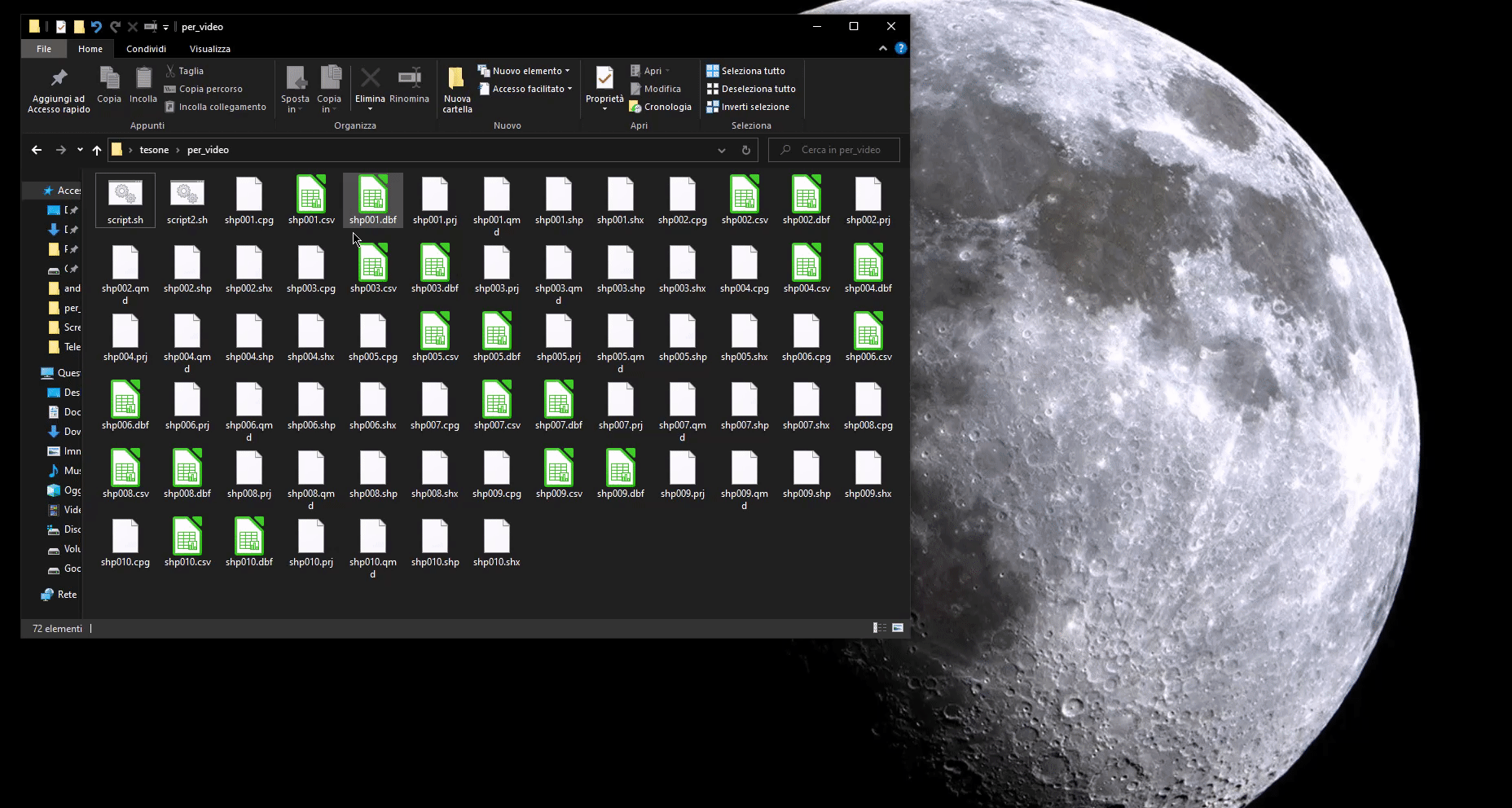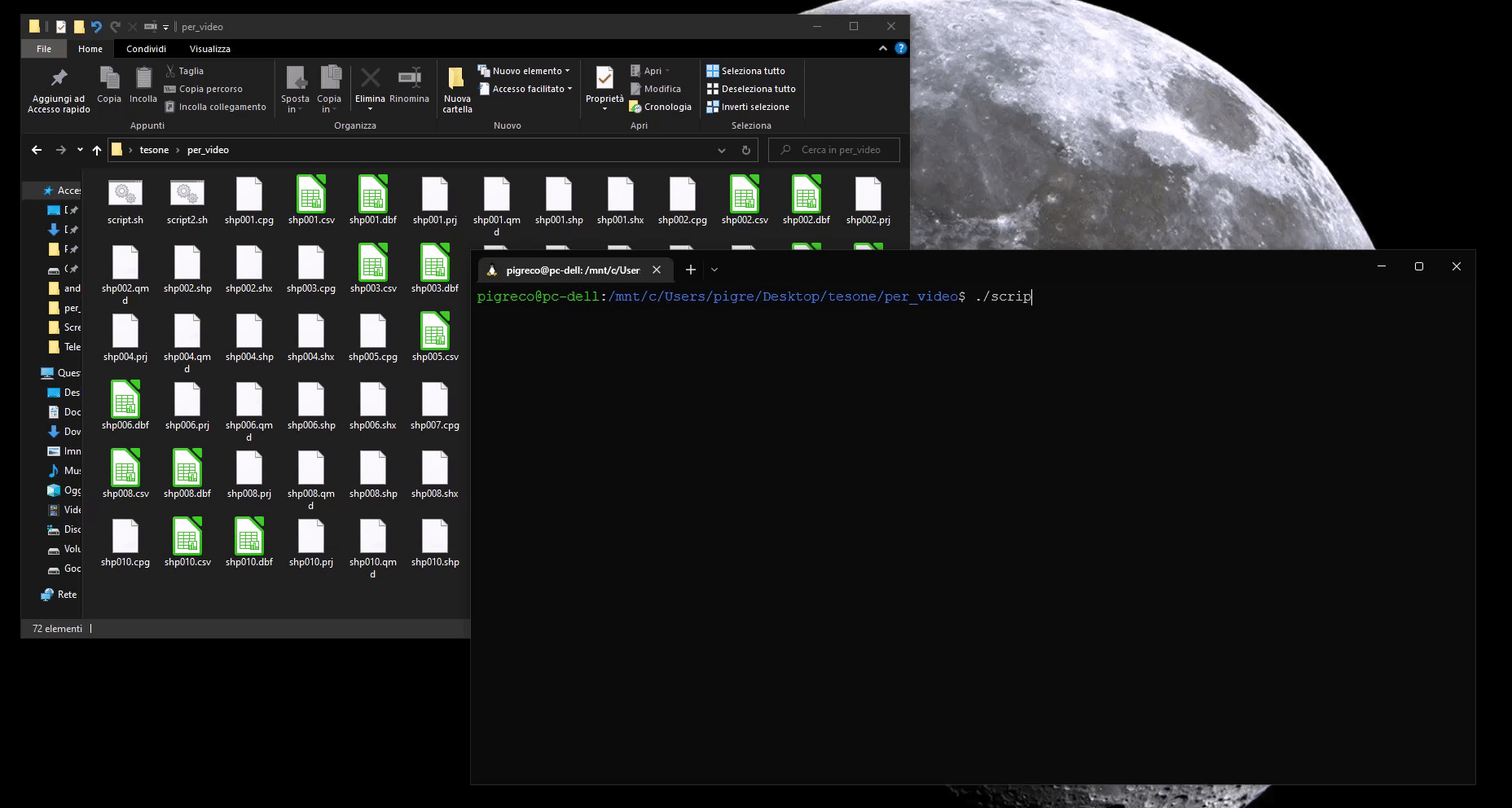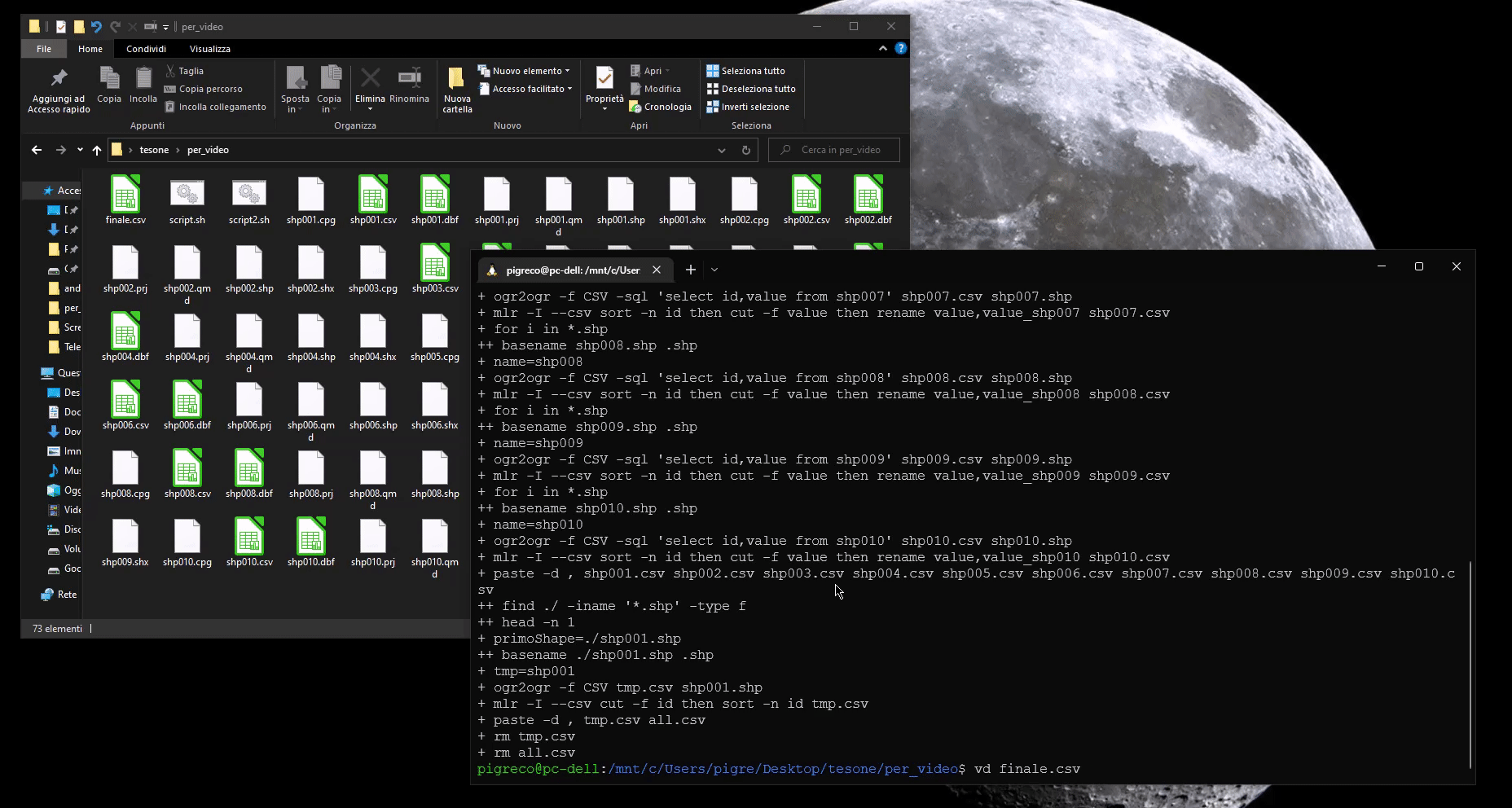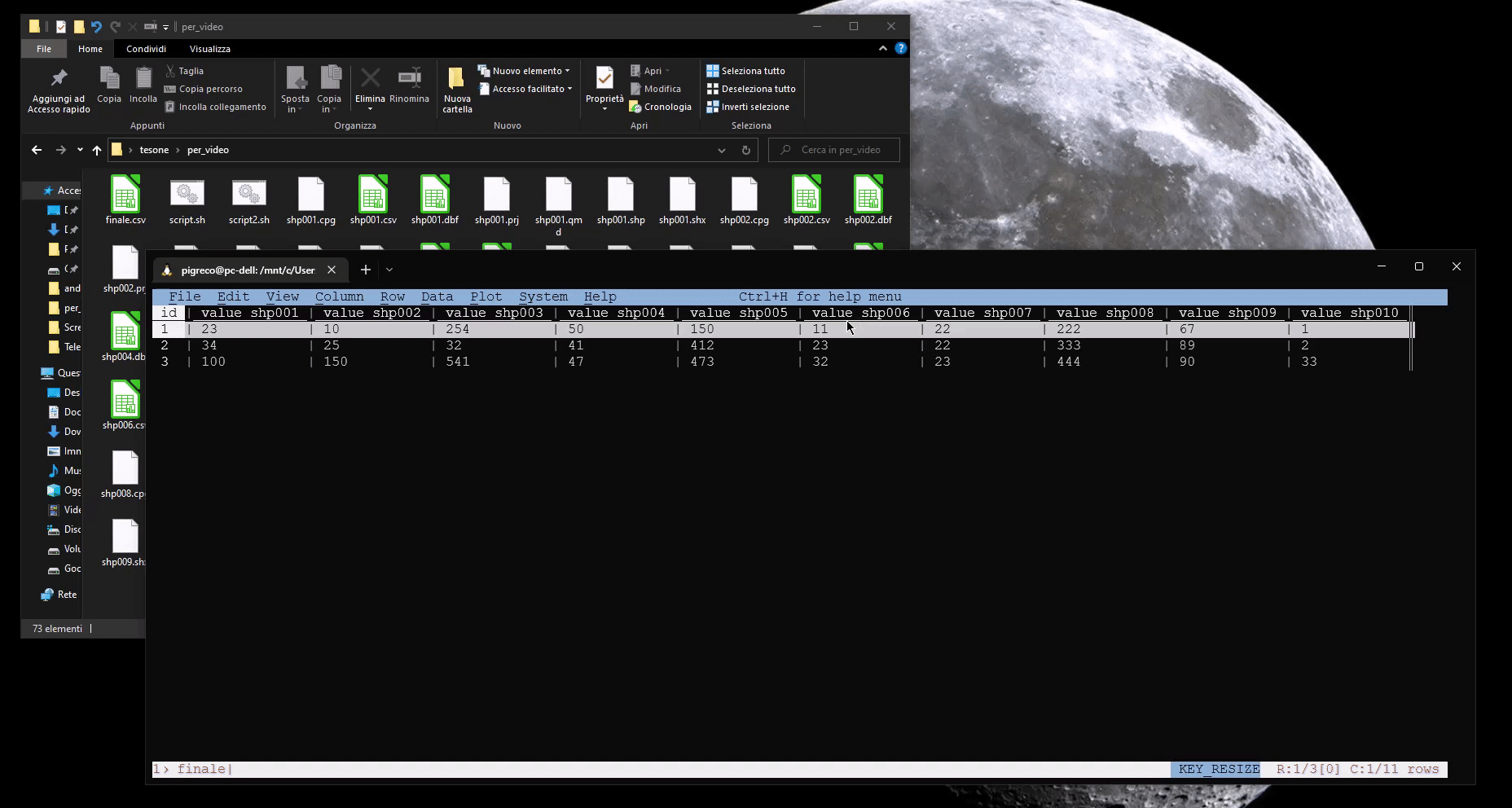
paste -d "," tmp.csv all.csv > finale.csv
# rimuove file inutili
rm tmp.csv
rm all.csv
# realizzato da Andrea Borruso
da questo script bash otterremo un unico file CSV (finale.csv) pronto per essere messo in JOIN con il primo vettore:

Seconda soluzione ambiente bash (linux)
fare un normalissimo fondi vettori, ovvero, unione verticale di tutti i vettori; successivamente, convertire l’unico vettore in file CSV; infine, convertire il file CSV da wide a long:
#!/bin/bash
#### RIFERIMENTI #####
# ogr2ogr : https://gdal.org/programs/ogr2ogr.html
# ogrmerge.py : https://gdal.org/programs/ogrmerge.html
# miller : https://github.com/johnkerl/miller
####################
# unisci in verticale gli shape
ogrmerge.py -overwrite_ds -single -src_layer_field_name layer -o merged.shp shp*.shp
# converti lo shape in CSV
ogr2ogr -f CSV merged.csv merged.shp
# converti il CSV da wide a long
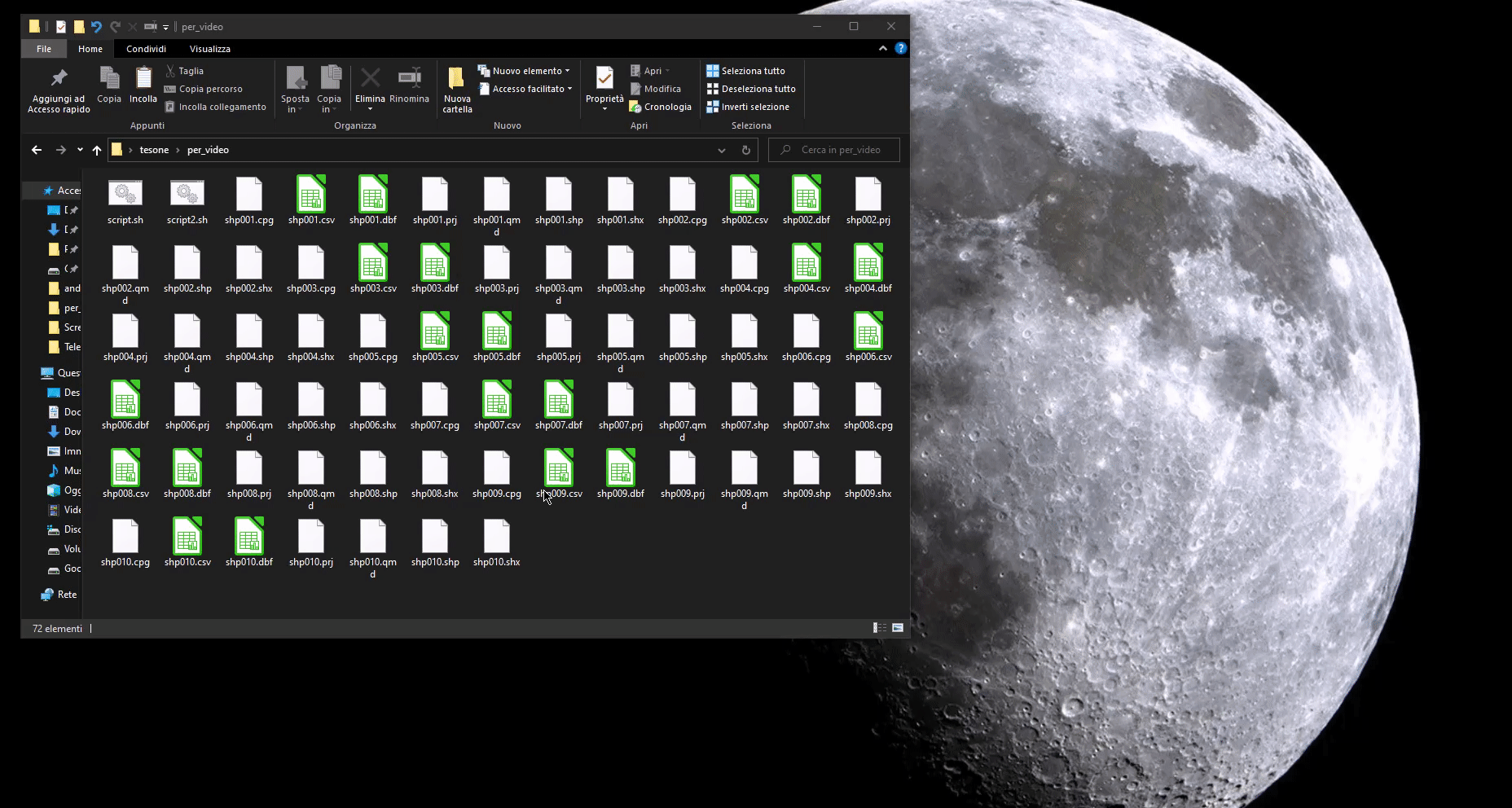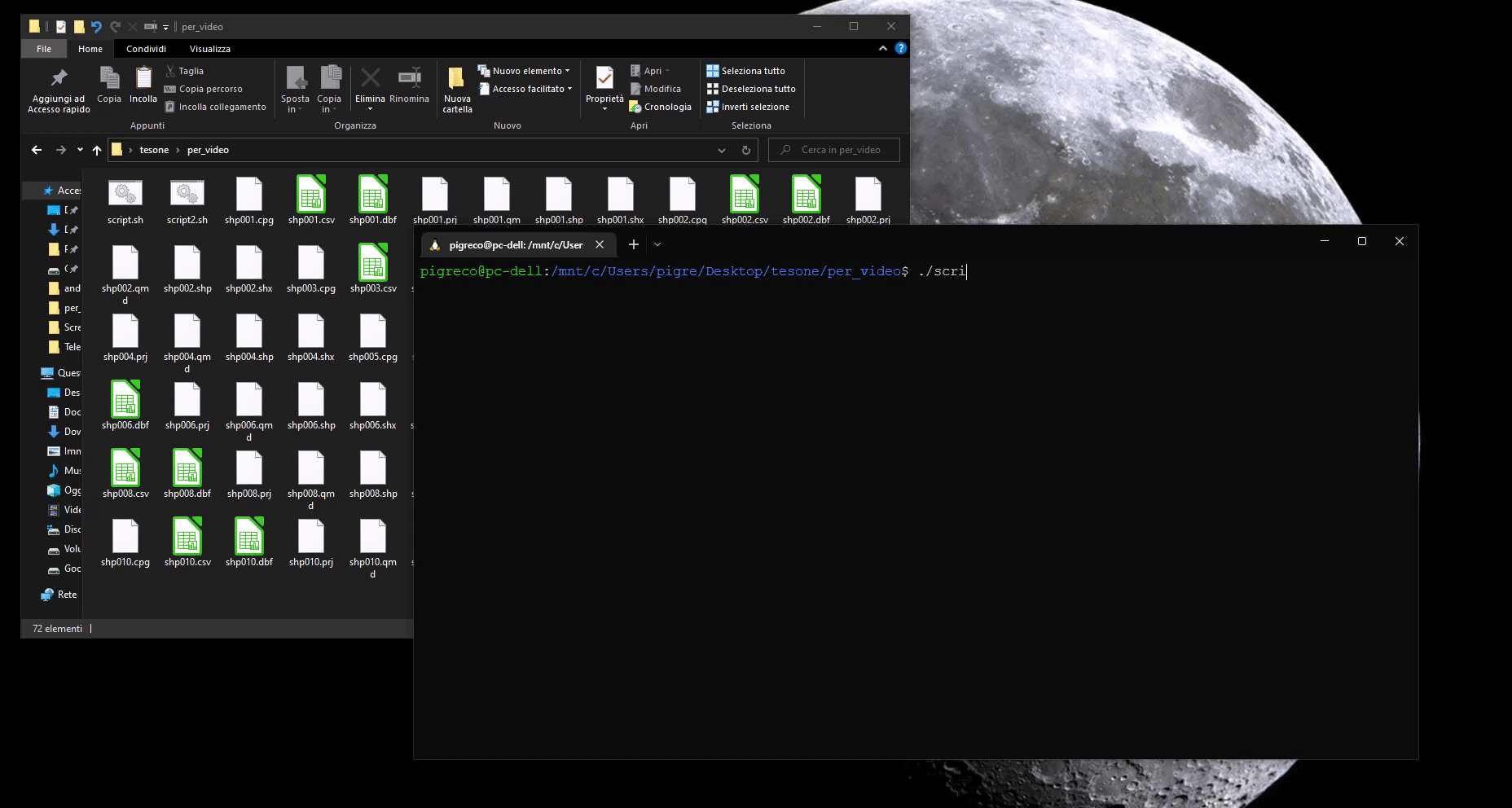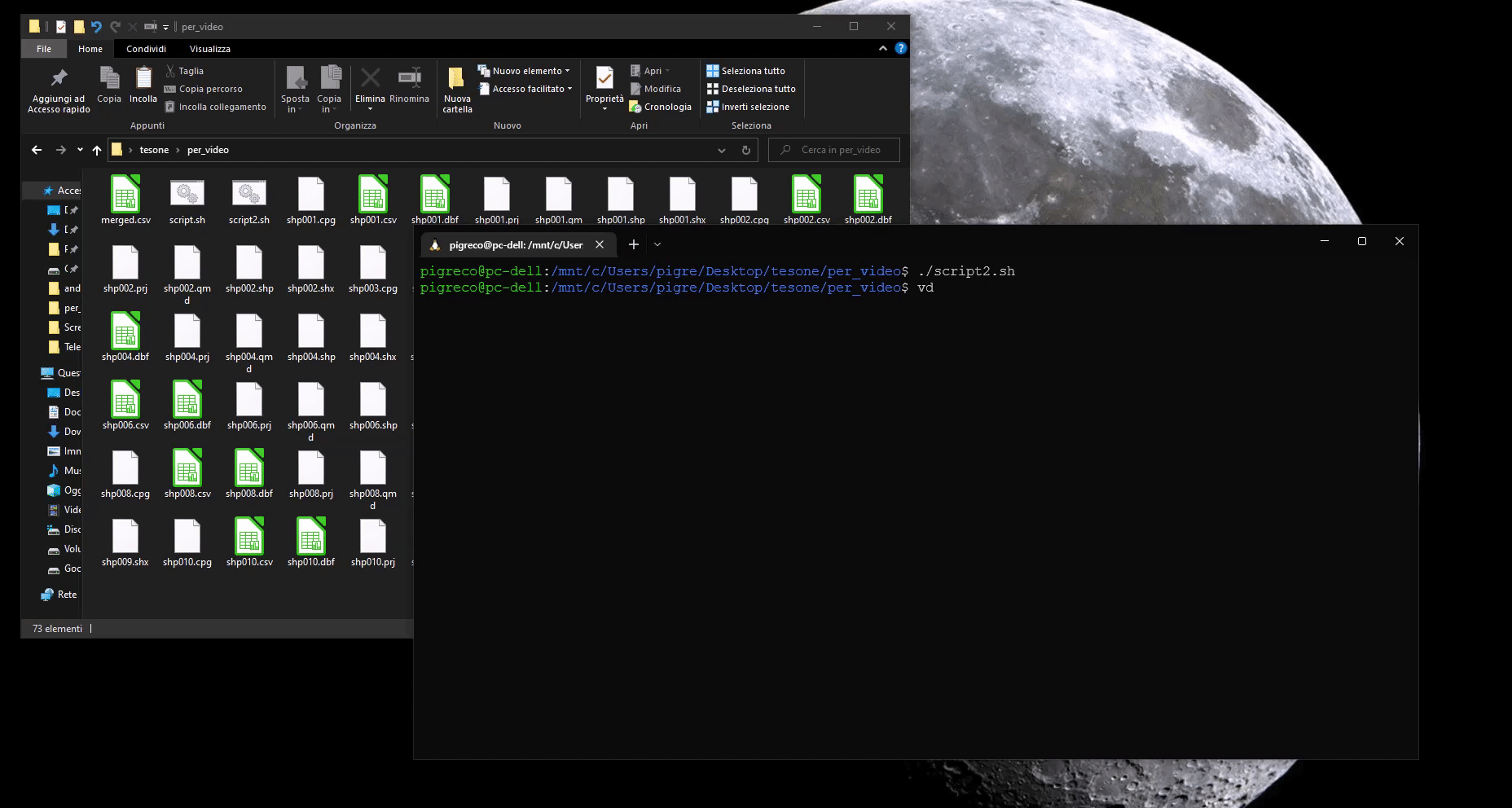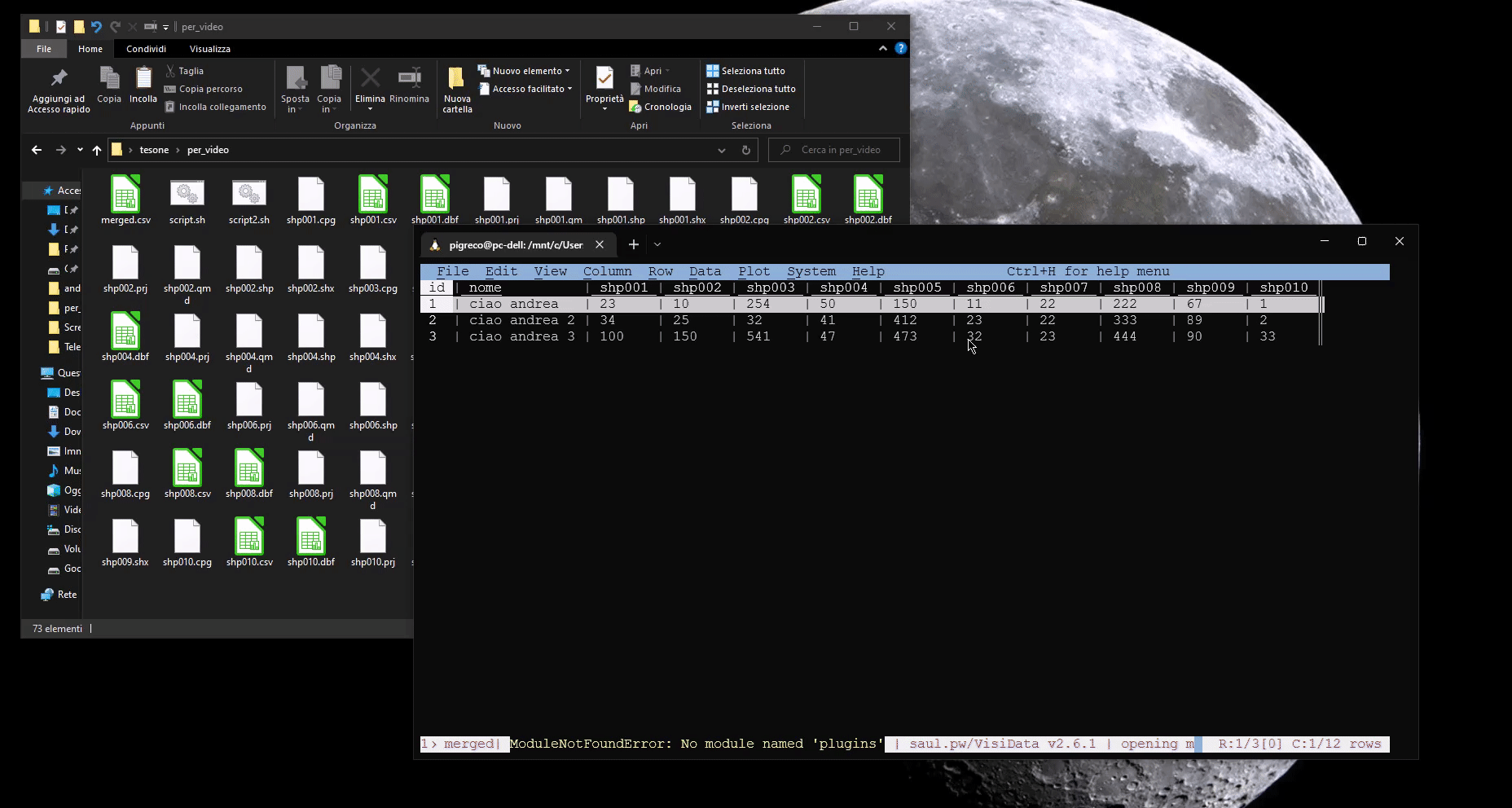
mlr -I --csv reshape -s layer,value merged.csv
# cancella file inutili
rm merged.shp
rm merged.shx
rm merged.prj
rm merged.dbf
# realizzato da Andrea Borruso
da questo script bash otterremo un unico file CSV (merged.csv) pronto per essere messo in JOIN con il primo vettore (che conterrà anche la geometria):

Terza soluzione ambiente Python
usando Python e geopandas
import glob
import geopandas as gpd
files = glob.glob("../data/andrea/*.shp")
files.sort()
gdf = gpd.read_file(files[0])
gdf.rename(columns={'value':f'value_shp001'}, inplace=True)
for f in files[1:]:
name = f[f.rfind('/')+1:-4]
gdf2 = gpd.read_file(f)
new_column = f'value_{name}'
gdf2.rename(columns={'value': new_column}, inplace=True)
gdf = gdf.merge(gdf2[['id',new_column]], on='id')

In questo caso otterremo un unico vettore con tutte i campi uniti!!! (Grazie a Giovanni Pirrotta)
TUTTO con QGIS
Plugin Group Stats
Soluzione usando solo QGIS e il plugin Group Stats:
- Usare algoritmo di Processing
Fondi Vettori, per ottenere una unione verticale dei vettori; - Usando il plugin, creare una tabella Pivot;
- salvare la tabella Pivot in CSV e modificare l’intestazione;
- infine, fare una JOIN tabellare.

Plugin
Per chi ama i bottoni, ecco la soluzione definitiva e immediata, tramite Plugin per QGIS realizzato da Giulio Fattori: in INPUT (Get File:): selezionare il file (shp o gpkg), il campo correlato (Join Field:) e campo da unire (Data field:); in OUTPUT, direttamente il vettore con tutti gli attributi uniti.
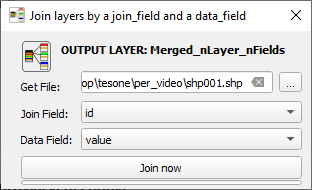
Il plugin è disponibile nella repository ufficiale di QGIS, con relativa guida.
NOTE FINALI: sicuramente esistono altri approcci per risolvere il quesito (probabilmente anche tramite mapshaper), ma credo di aver proposto varie soluzioni, anche per vari ambienti e per tutti i palati: per chi ama la riga di comando fino a chi ama pigiare solo i bottoni 🙂
RIFERIMENTI
- Ricetta T’ansignari : https://tansignari.opendatasicilia.it/ricette/riga_comando/multi_join/
- ogr2ogr : https://gdal.org/programs/ogr2ogr.html
- ogrmerge.py : https://gdal.org/programs/ogrmerge.html
- Miller : https://github.com/johnkerl/miller
- Geopandas : https://geopandas.org/en/stable/
- VisiData : https://ondata.github.io/guidaVisiData/
- pyQGIS : https://docs.qgis.org/3.22/en/docs/pyqgis_developer_cookbook/index.html
- Plugin Group Stats : https://plugins.qgis.org/plugins/GroupStats/
RINGRAZIAMENTI
- Andrea Borruso
- Giovanni Pirrotta
- Giulio Fattori
- Giuliano Ramat
DATI PER TEST
I MIEI CANALI – ISCRIVITI
- Telegram : https://t.me/pigrecoinfinito
- YouTube : https://www.youtube.com/c/TotòFiandaca
Se il blog post Ti è piaciuto cliccate su ‘Mi piace’, grazie!!!
if you liked the blog post click on ‘Like’, thank you !!!
