

Appuntamento ai Cantieri Culturali alla Zisa dove troviamo l’inaugurazione di una piazza dedicata a Fabrizio De Andrè (la foto di sopra è un murales realizzato per l’evento – autore foto gbvitano).
Ma facciamo un passo indietro: la sera prima preparo il laptop da portare a Palermo e usarlo durante l’esercitazione con VisiData e Miller, ma alle ore 10:00, dopo quasi due ore di viaggio e 150 km percorsi, raggiunto il parcheggio alla Zisa sono assalito da un dubbio atroce: ma ho preso il notebook?? NOoooooo!!! dimentico lo strumento sulla sedia dello studio. 😦

Doveva partecipare anche Ciro ma la febbre l’ha costretto a stare a casa.
In anteprima mondiale l’agenda e il nuovissimo laptop di Andrea:
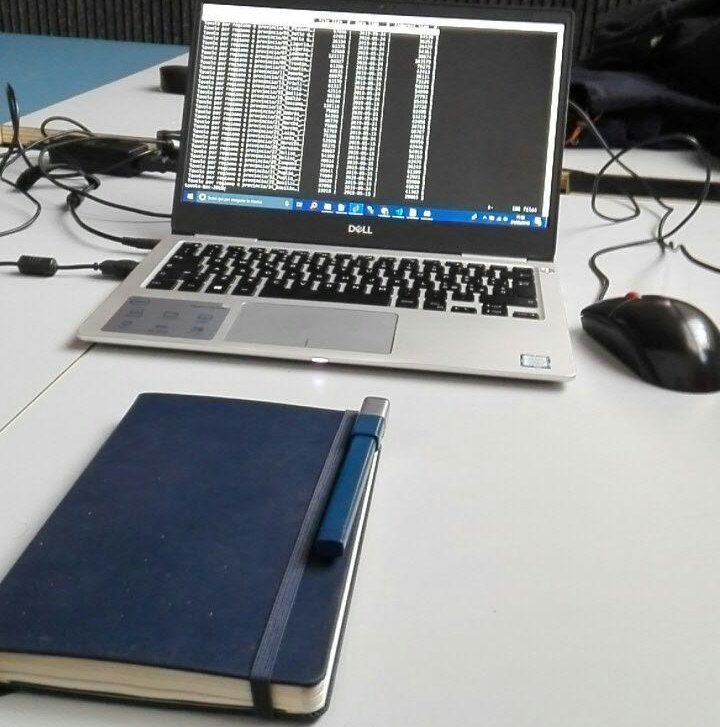
Andrea inizia parlando dei dati messi a disposizione dall’ ISTAT, indicatori del Bes nelle province e città metropolitane italiane, e ci fa notare subito che hanno una struttura poco usabile:
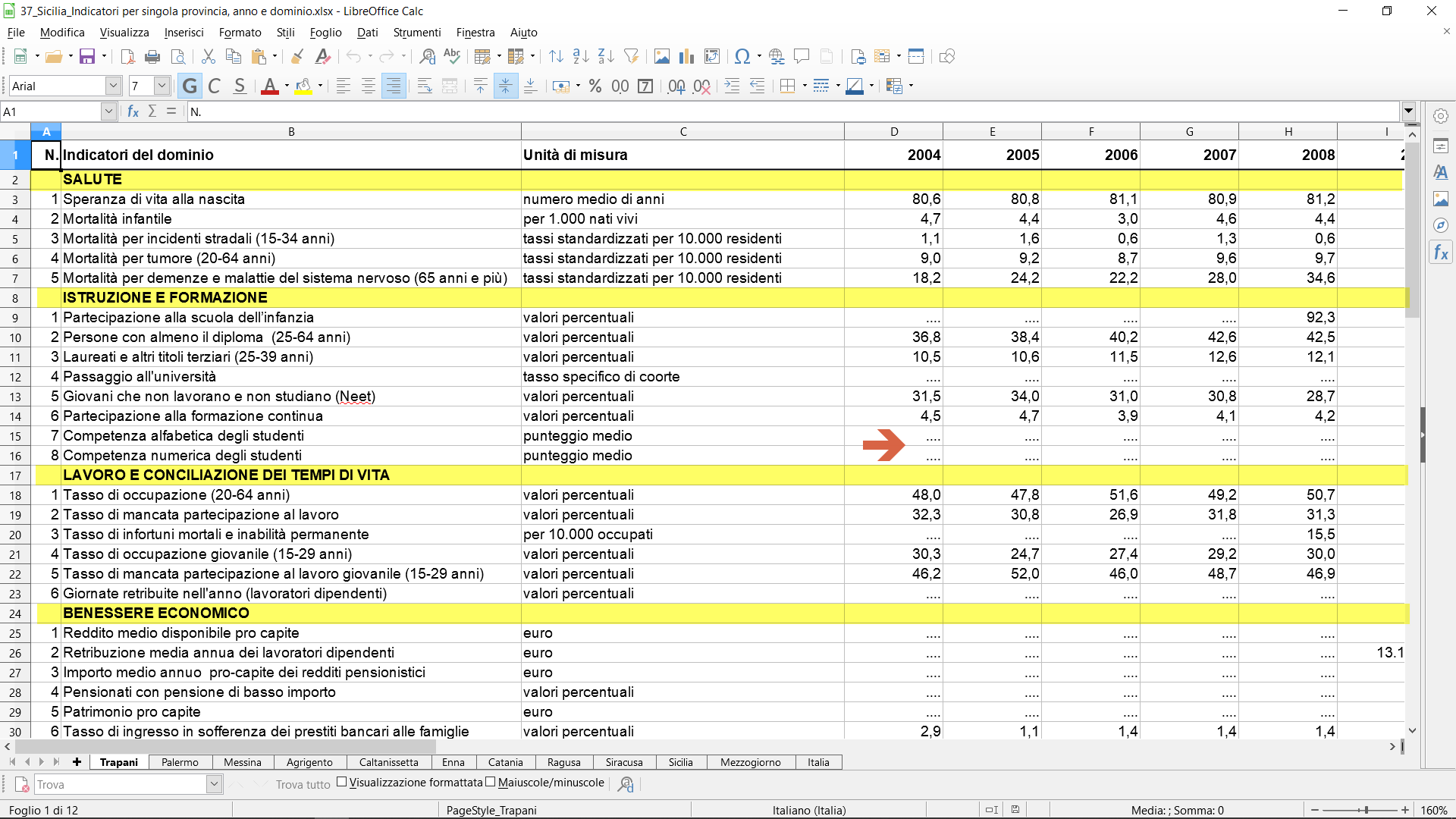
in giallo righe usate come intestazioni; valori NULL con i puntini …. ed altri errori.
In meno di tre ore Andrea ci spiega come rendere usabile questi dataset usando la riga di comando e due tool grandiosi: VisiData e Miller.
Usando VisiData:

tradotto in testo:
- digitare gz* e scrivere: \.\.+/ invio;
- con le frecce spostarsi nella colonna ‘Indicatori del dominio’ e digitare SHIFT+^ per modificare e scrivere IndicatoriLong;
- spostarsi nella colonna ‘Unita di misura‘ e digitare za per aggiungere un campo e poi digitare Indicatori;
- posizionarsi nella prima colonna ‘N.‘ e prima riga e digitare , (virgola) verranno selezionati tutte le righe che hanno quella caratteristica;
- posizionarsi nella colonna appena aggiunta e digitare g= e scrivere il nome del campo modificato al punto 2 IndicatoriLong e invio;
- digitare gu per deselezionare;
- digitare la f per il fill-down;
- ripetere il punto 4 per selezionare le righe;
- cancellare le righe selezionate digitando gd;
- spostarsi nella prima colonna e digitare SHIFT+! per renderla indice, ripetere per le altre tre colonne;
- digitare M per il Melt;
- digitare CTRL+S per salvare.
Usando Miller:
#!/bin/bash
set -x
# crea variabile temporanea per memorizzare il nome della cartella
folder="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
# rimuovi dalla cartella ogni CSV
rm "$folder"/*.csv
# estrai dal file xlsx tutti i fogli come CSV
# vengono creati dei CSV con nome che inizia con tmp__ seguito dal nome del foglio
pyexcel transcode "$folder"/"37_Sicilia_Indicatori per singola provincia, anno e dominio.xlsx" "$folder"/tmp.csv
# per ogni FILE CSV creato fai pulizia e ristrutturazione con Miller
for i in "$folder"/*.csv; do
# crea una variabile per raccogliere il nome di ogni file CSV, senza estensione
nomefile=$(echo "$i" | sed -r 's|^(.*\/)(.+)(\.csv)$|\2|g')
# crea una variabile per creare un nome di output dei file senza il suffisso tmp__ e senza estensione
nome=$(echo "$i" | sed -r 's|^(.*\/)(tmp__)(.+)(__)(.+.csv)$|\3|g')
# fai la pulizia e ristrutturazione con Miller
mlr --csv clean-whitespace \
then put -S 'if (${Unità di misura} == "") {$Indicatore = ${Indicatori del dominio}} else {$Indicatore = ""}' \
then fill-down -f Indicatore \
then filter -S '${Unità di misura} != ""' \
then put -S 'for (k in $*) {$[k] = gsub($[k], "\.\.+", "");}' \
then put -S 'for (k in $*) {$[k] = gsub($[k], "^-+$", "");}' \
then reshape -r "^2" -o anno,valore \
then reorder -f Indicatore \
then put -S '$foglio="'"$nome"'"' \
then filter '$valore>-999999' \
then sort -f foglio,Indicatore -n anno,"N." "$folder"/"$nomefile".csv >"$folder"/"$nome".csv
done
# rimuovi tutti i CSV con nome con suffisso tmp__
rm "$folder"/tmp_*.csv
# crea un unico file di insieme
mlr --csv cat "$folder"/*.csv >"$folder"/Sicilia_Indicatori_per_singola_provincia_anno_e_dominio.csvil codice va copiato e incollato in un editor di testo e salvato bes.sh
Miller non supporta i file xlsx di excel e quindi occorre preliminarmente trasformare il file in csv, per far questo occorre usare l’utility pyexcel che si installa cosi:
# si scrivi questo primo comando e si da invio
python3 -m pip install --user --upgrade pyexcel-cli
# e se tutto procede per bene si aggiunge il supporto per i file xlsx
python3 -m pip install --user --upgrade pyexcel-xlsxdopo l’installazione portatevi nella cartella che contiene il file xlsx e lanciate il seguente codice:
pyexcel transcode ./"37_Sicilia_Indicatori per singola provincia, anno e dominio.xlsx" tmp.csvcreerà tanti file csv quanti sono i fogli presenti nel file xlsx.
lo script bes.sh va lanciato a partire da questa cartella:
video demo:
NOTE FINALI: Purtroppo uso ancora poco la riga di comando ma resto sempre impressionato dalla potenza di questo strumento e soprattutto dalle sue utility come in questo caso VisiData e Miller: Visidata per singolo file e Miller per agire su insiemi di file. Vedere in azione Andrea è il miglior modo per apprezzare e innamorarsi della riga di comando.
Riferimenti:
Ringraziamenti:

Caro Totò è un post che mi fa scendere la lacrimuccia. Sono fortunato ad avervi incontrato.
È stata una mattinata molto bella, come essere in vacanza con i compagni del liceo!!!
"Mi piace"Piace a 2 people
Permettimi di sottolineare che il fortunato tra noi due sono io.
È stato un bel viaggio, comico per alcuni versi, ma molto didattico.
"Mi piace"Piace a 1 persona