Un amico mi passa la seguente tabella:
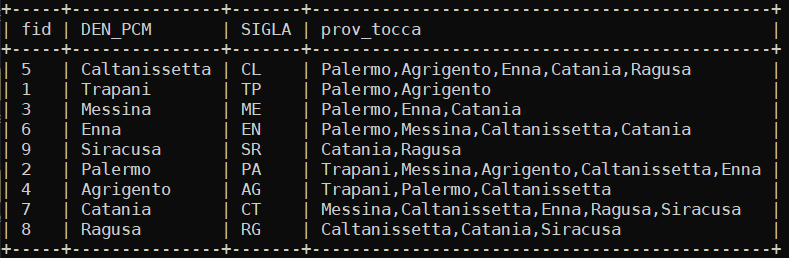
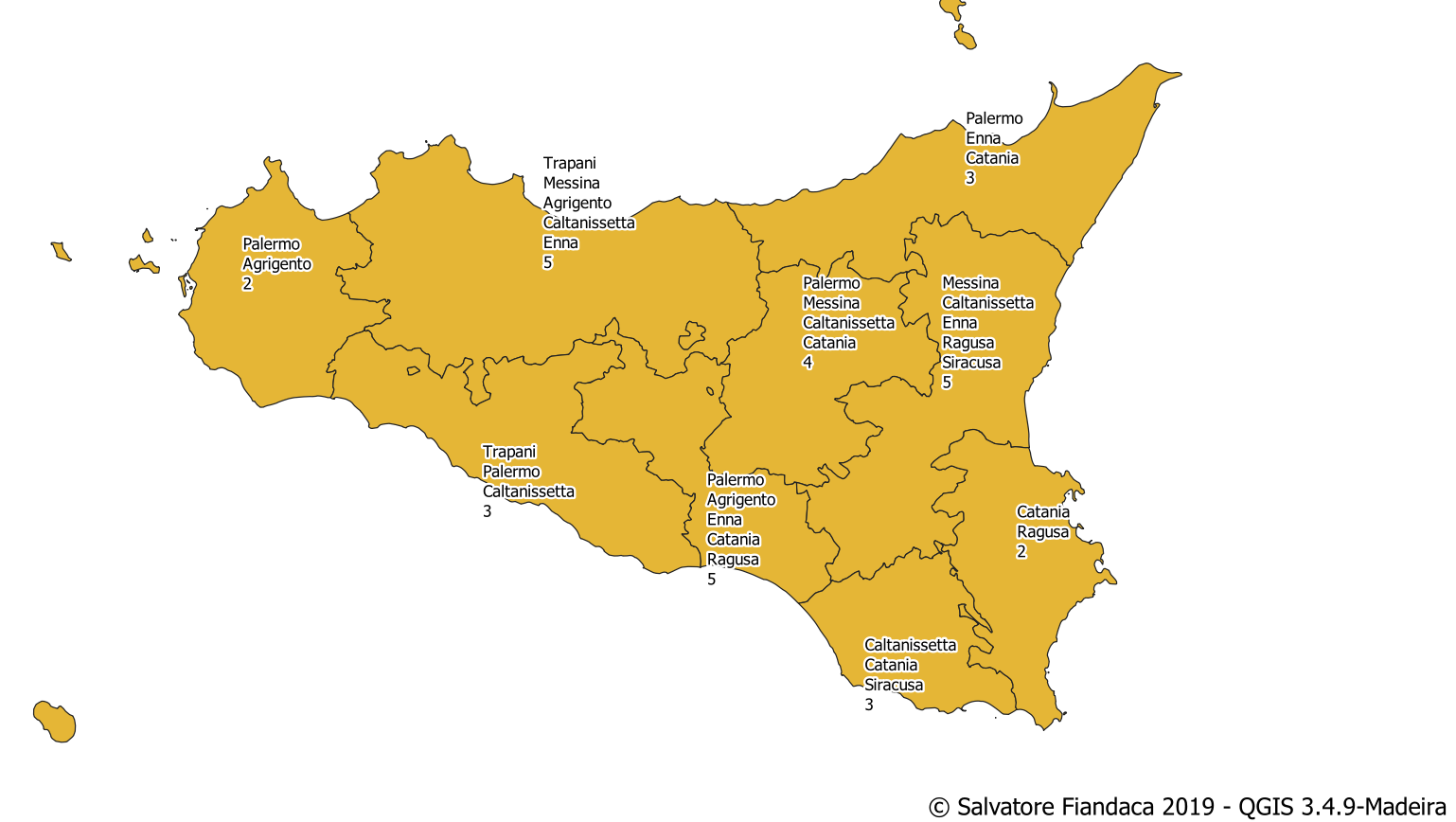
La quarta colonna (prov_tocca) di questa tabella (sicilia.csv ) contiene i nomi delle province che toccano la provincia corrente presente nella seconda colonna (DEN_PCM), cioè Caltanissetta è confinante (toccata spazialmente) con le province di: Palermo, Agrigento, Enna, Catania e Ragusa.
L’amico curioso mi chiede: quante volte è presente il nome Palermo nel quarto campo (prov_tocca)?? In questo caso specifico la risposta è banale, ma il quesito generale è: Conteggi aggregati di campi con multivalore: in generale i valori presenti nel secondo campo sono diversi da quelli presenti nel quarto campo.
La mia risposta: usando SQLite o un Layer Virtuale in QGIS, la query che risolve il quesito è:
WITH recursive splitvalues(fid, val, more) AS (
SELECT fid, '', replace(prov_tocca, ', ', ',') || ','
FROM "Sicilia"
UNION ALL
SELECT fid, substr(more, 0, instr(more, ',')), substr(more, 1+instr(more, ','))
FROM splitvalues
WHERE more <> ''
)
SELECT trim(val, ', ') AS prov, count(*) AS n
FROM splitvalues
WHERE val <> ''
GROUP BY val
ORDER BY val;risultato:
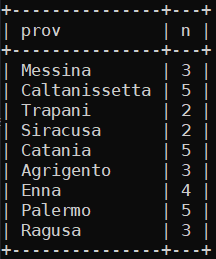
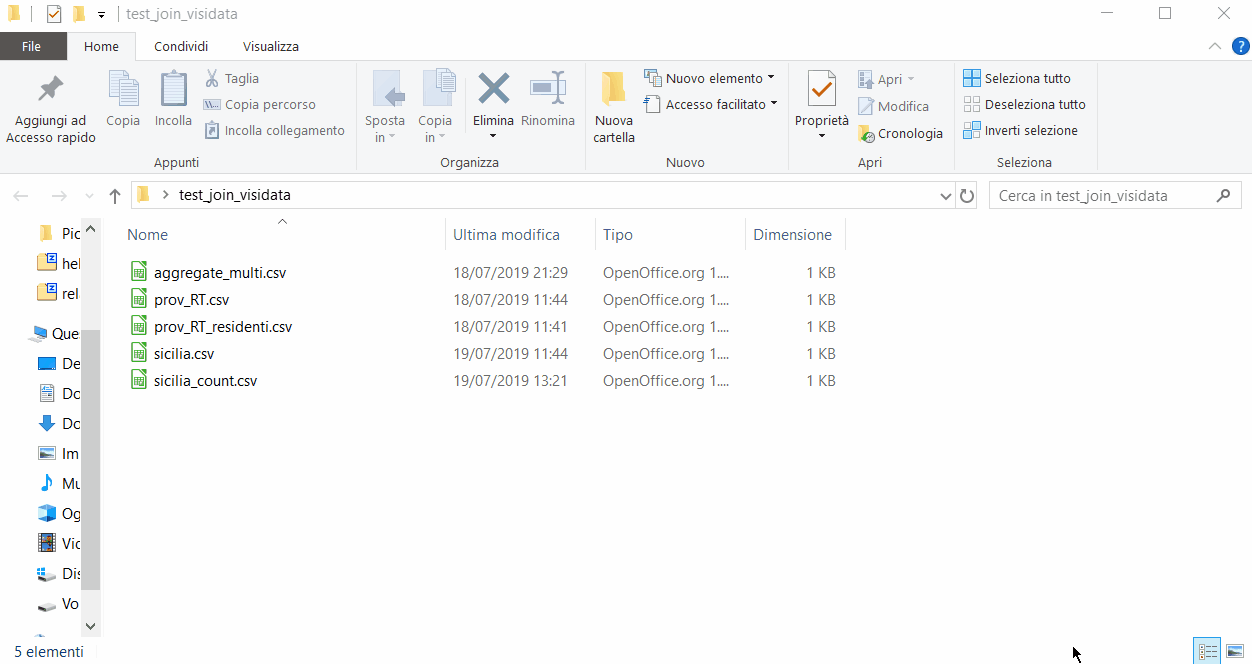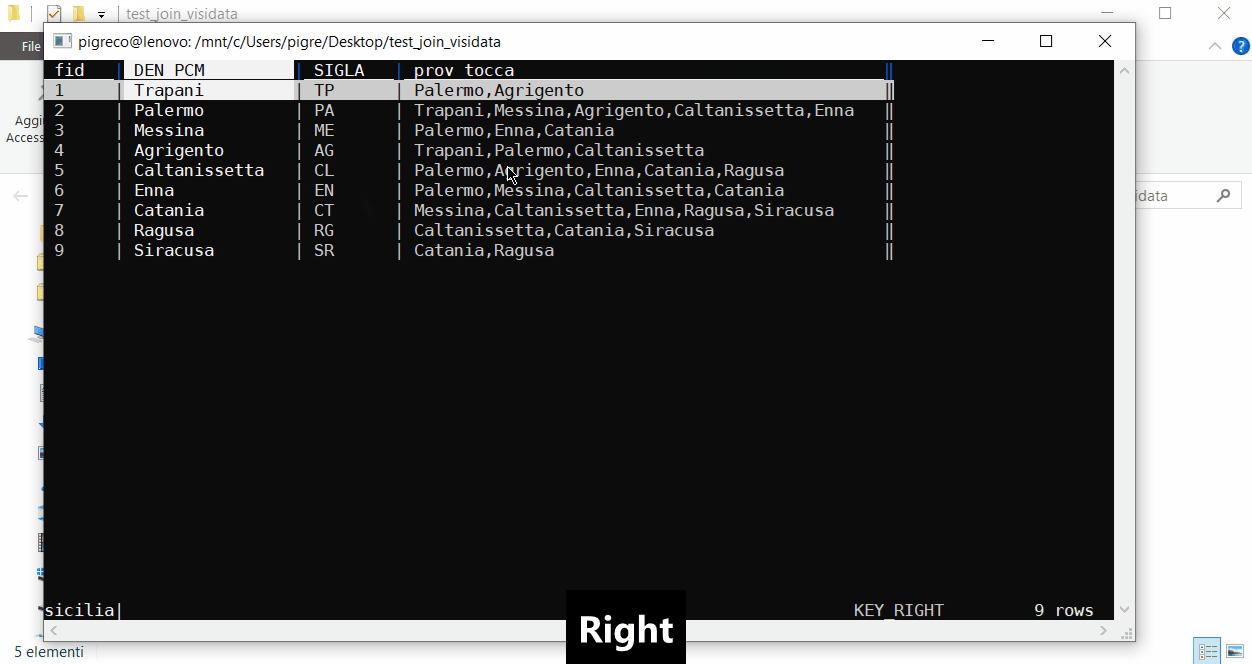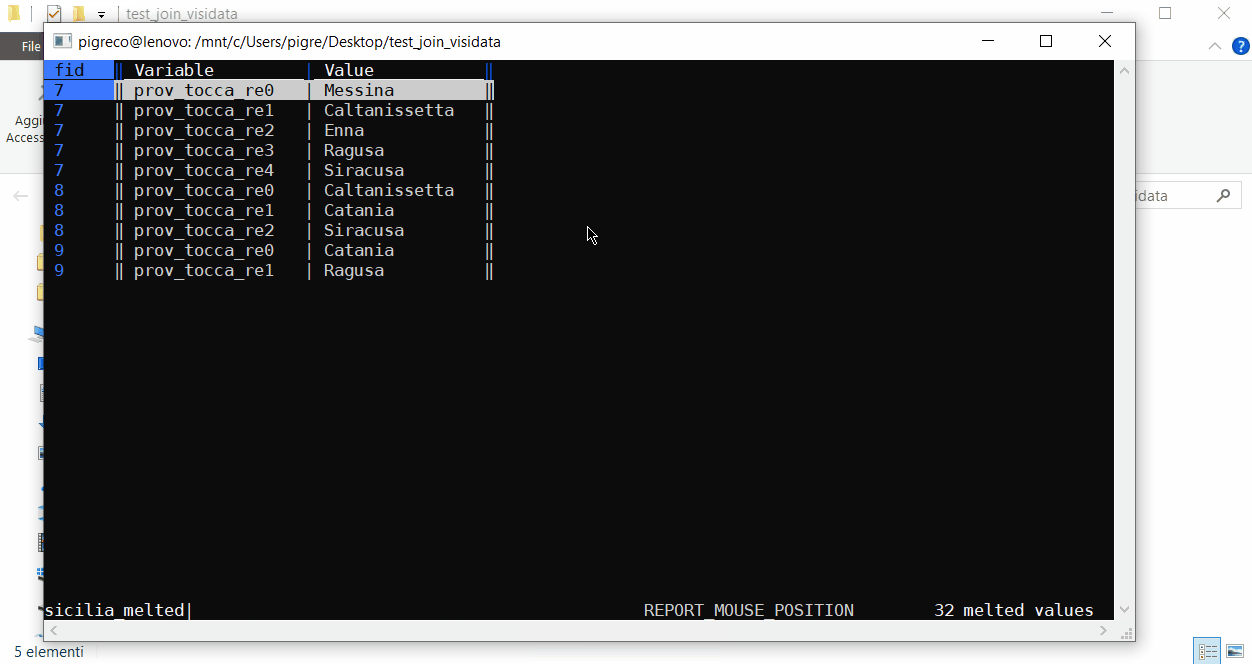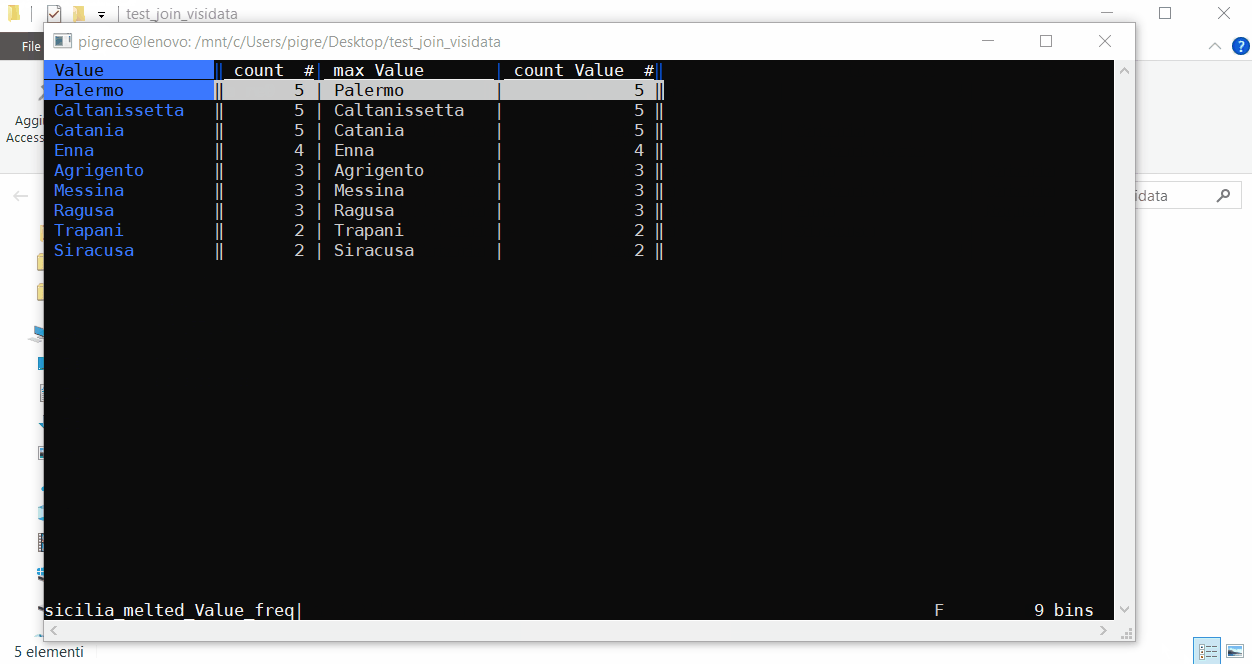
cioè la provincia di Messina è presente tre volte nel campo ‘prov_tocca‘ della prima tabella; Caltanissetta è presente 5 volte e cosi via per le altre province.
Faccio un piccola verifica usando VISIDATA:
- apro file (vd sicilia.csv);
- Shift+! sul campo fid per renderla chiave primaria;
- navigo fino all’ultimo campo prov_tocca e sposto il cursore nella riga con più elementi e digito Shift+: (per splittare colonna) [oppure: sulla colonna prov_tocca digito = prov_tocca(‘,’) e invio e poi ordino dopo aver digitato #];
- alla richiesta split regex: digito , (virgola e invio);
- nascondo le colonne che non mi servono digitando – : prov_tocca, SIGLA e DEN_PCM;
- navigo fino a fid e Shift+m (per il melted);
- navigo fino alla colonna Value e digito +
- alla richiesta digito count (per contare le occorrenze) e invio;
- digito Shift+f sempre sul campo Value;
- Fatto!!!
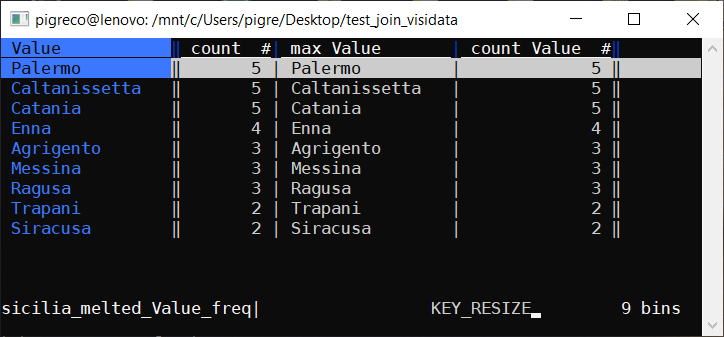
Ulteriore verifica usando Miller:
mlr --c2p --barred nest --explode --values --across-fields --nested-fs "," -f prov_tocca then reshape -r "tocca" -o item,value then count-distinct -f value then sort -nr count sicilia.csv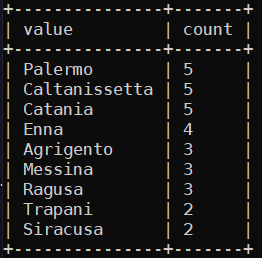
Riferimenti:
- QUERY SQL: http://www.samuelbosch.com/2018/02/split-into-rows-sqlite.html
- SQLite: https://www.sqlite.org/index.html
- Guida VisiData: https://github.com/ondata/guidaVisiData/tree/master/testo#Aggiunta-di-aggregatori
- Miller: http://johnkerl.org/miller/doc/10-min.html
- QGIS: https://qgis.org/it/site/
Dati:
- file csv per provare
